We Protect You
From People Like Us.
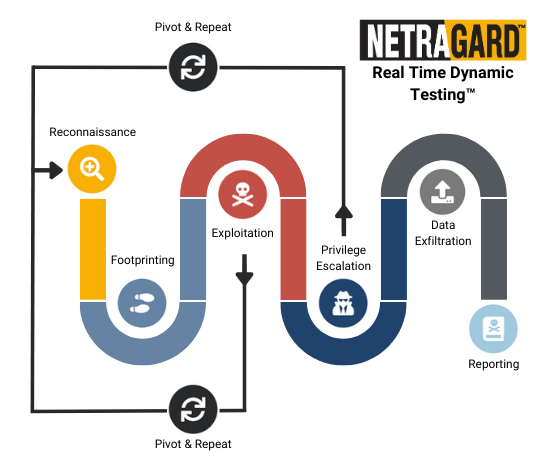
We deliver Advanced Penetration Testing Services backed by over 15 years of experience in vulnerability research and exploit development with our proprietary methodology of Real Time Dynamic Testing™